What happens if The New York Times wins their case against OpenAI?
Low-risk models and the challenges of "extreme domain generalization".


At this point, we all know that whatever dataset OpenAI used to train their GPT models contains articles from The New York Times. OpenAI has not publicly released their training data, but sometimes their model will enthusiastically “regurgitate” a Times article, so it’s not a secret what’s going on. The Times is suing and the AI industry is bracing for a legal battle that could define the future of commercial applications for generative models.
The lawsuit contains many cringy examples where ChatGPT spits out near-verbatim versions of Times articles. (H/t to whatever lawyer decided to typeset the plagiarized text in bright red, really drives home the point). The thing is that despite the wow factor and the pages of red text, memorization is a squashable bug of LLM systems—not a core feature.
OpenAI has already made it much harder to reproduce the examples in the lawsuit, and they’ll surely get better at building guardrails over time. Remember, OpenAI does not sell direct access to its models: it sells access to its models wrapped in a bunch of business logic to control the output. Detecting if text is very similar to other text is a solved problem and I have no doubt that they can build a sophisticated Publisher Memorization Detection System to shove into their business logic layer.
That said, The Times could win. Copyright law is murky, often inconsistent and evolves alongside new technology. In Harper & Row v. Nation Enterprises, the Supreme Court ruled that a 250-word passage constituted the “heart” of a larger autobiography and was not covered by fair use. On the other hand, Google was allowed to show a portion of books in their Google Books product because the use case was considered “transformative.” If you want to learn more about the relevant copyright law, “Foundation Models and Fair Use” gives a great overview of the legal risks of generative AI models.
What would be fascinating—but we won’t get to see—would be a comparison of GPT-4 trained with and without Times data. My guess is that the version without Times data would be worse, and not because you’ll no longer be able to read the Pete Wells review of Guy Fieri’s American Kitchen & Bar by prompting a chatbot for the article one paragraph at a time. It will be worse because professionally written text is a valuable resource on the internet. Businesses want AI systems that use professional vocabulary, that don’t make grammatical errors and that don’t call people bad names. On the other end of the spectrum, everyday users want AI systems that don’t sound like lawyers or UN proceedings.
A large quantity of text that is professional, clear, and authoritative without being overly formal is incredibly useful to people who build AI models for profit, but the impact of Times data on the “style” of generated text is hard to quantify and would be a weaker copyright infringement case. A system that only extracts the writing style from a corpus of text would likely pass the fair use bar of adequately “transforming” the data.
In any case, we will have to wait and see what happens with the lawsuit. What I really want to talk about is what will happen if The Times wins and is able to restrict the data used to train generative text models.
What are these models trained on today? “The Times!” you say — and that is correct — but there is a lot more. Once it became clear that big models trained on big data deliver big results, researchers from academic labs and employees at AI startups wrote scripts to scrape data from the internet and pirate books from torrent sites. Many of these datasets were released publicly alongside papers describing how they were generated.
The current biggest public-ish training dataset is 800GB of text known as The Pile created by Eleuther AI and described in the 2020 paper, “The Pile: An 800GB Dataset of Diverse Text for Language Modeling.” It contains data from Wikipedia, Github, Books3 (a collection of 191,000 eBooks that has been taken down after The Atlantic wrote about it), PubMed, a subset of data crawled from the internet by Common Crawl and much much more.
Some of this data is considered public domain and has no restrictions on its use (e.g. the works of Shakespeare or books from long dead American writers). Some of it is software code with permissive licenses such as MIT, Apache and BSD that is well protected by fair use. And some of it is free to use as long as it’s properly attributed (a rabbit hole we’re not going down now). However, much of the data does not have a clear license, and the legality of using it to train AI models will be battled out in the courts.
One path forward if The Times wins would be for the owners of the proprietary data to broker licensing deals with all of the builders of the LLMs, raising costs of the end users but otherwise keeping the architecture of the ecosystem the same. While some publishers have already inked licensing deals with OpenAI, this is not a viable path forward. For one, you would need COUNT(Important Datasets) x COUNT(Model Builders) x COUNT(Legal Jurisdictions) number of contracts. And even then, what if one of the Dataset Owners pulls their data? All of the Model Builders would need to delete the models that they spent millions of dollars to produce and train a new model from scratch without the banned data. Perhaps the research community will find a way to remove the influence of a subset of training data from a model, but until then, licensing deals alone will not provide a path out of the copyright infringement problem.
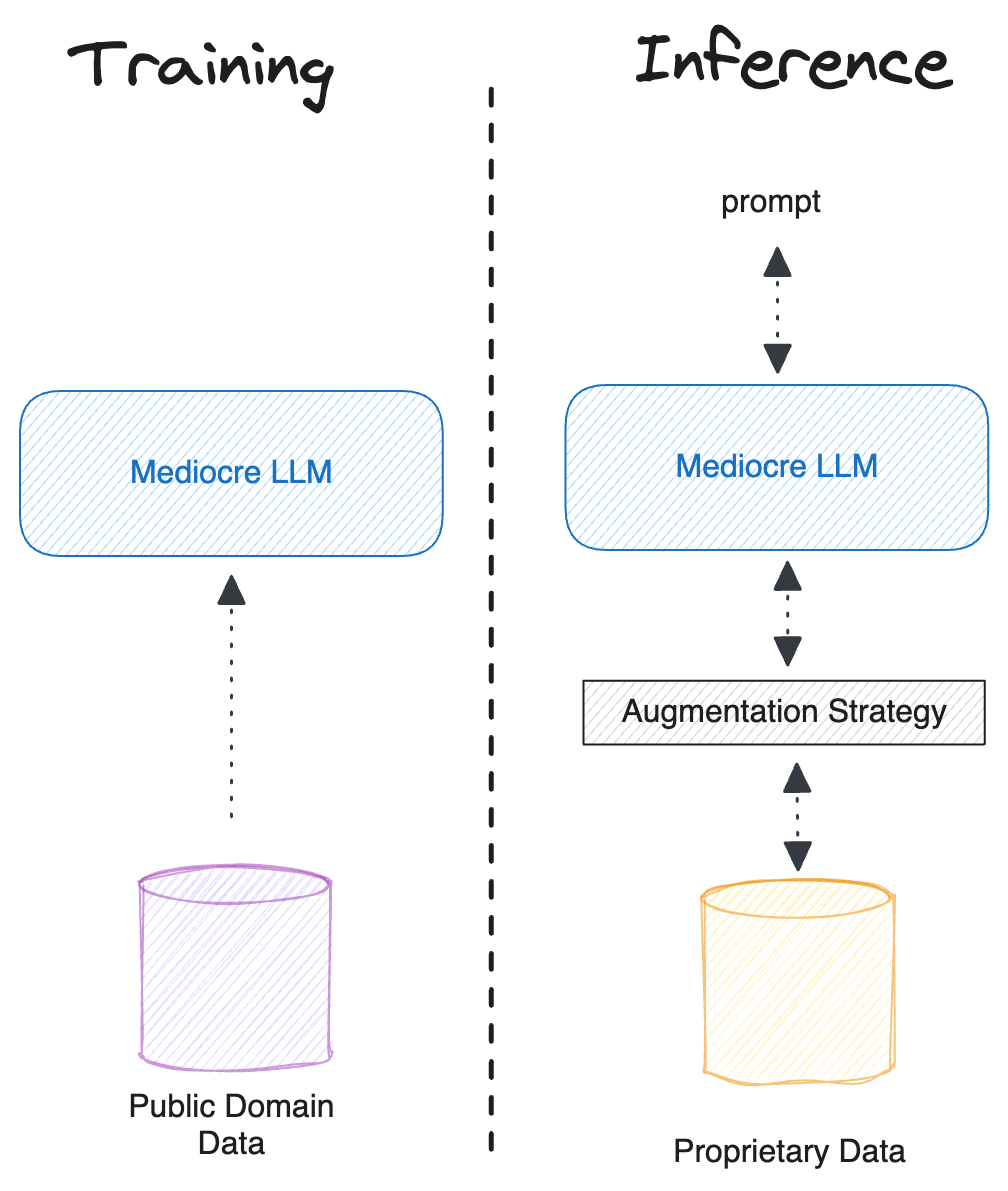
Luckily, the academic community that got us into this mess has some ideas to get us out of it. Last August, researchers from the University of Washington and UC Berkeley published a paper titled, “SILO Language Models: Isolating Legal Risk In A Nonparametric Datastore'' that proposed a way to leverage proprietary data outside of the model. The idea is that you train an LLM on all the “low-risk” data—all the stuff you won’t get sued for using—and then build a system around it that can leverage proprietary data to produce better results. The benefit of keeping the proprietary data separate from the model is that it can be swapped out without needing to retrain the model.
The authors created a new dataset they call the Open License Corpus (OLC) that is composed of text from scientific articles (31%), code (25%), legal documents (12%), message boards (12%) and several other domains. Text from news sources make up just 0.1% of the data because most articles do not meet the requirements of “open” data. The final dataset contains 228 billion tokens (a token is roughly a word), and is 31% smaller than the Pile.
The paper evaluates an LLM trained on this data against a baseline model called Pythia that was trained on the Pile data. Recall, language models are trained to predict the next word in a sentence given some “context” of previous words and they are evaluated by how accurately they can do this on new data. The authors find that their low-risk LLM is “competitive with Pythia despite using permissive data only,” with the significant caveat that it performs poorly on types of data that it has never seen before. It can accurately guess the next word when you feed it sentences from legal texts because it’s been trained on a bunch of legal documents, but it can’t guess the next word accurately if you feed it sentences from news articles because it was never taught to produce text in news speak.
One solution to this “extreme domain generalization challenge” is to build a system that can access information from proprietary data as it makes its next-word predictions. The paper proposes two ways to augment the predictions: one that uses the external data to augment the LLM prompt and one that uses the external data to change the probability distribution the model uses to predict the next word.
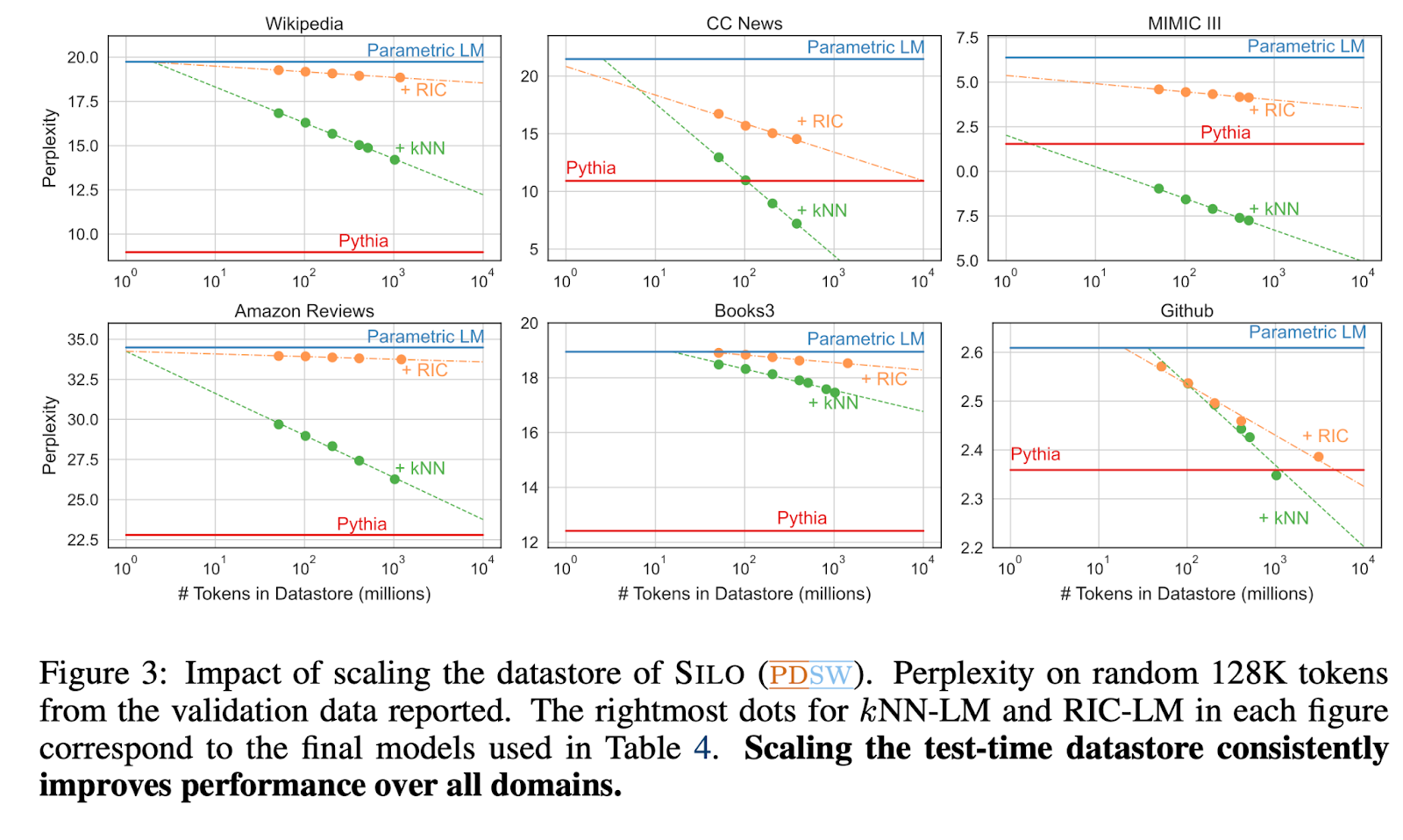
These augmentation strategies perform surprisingly well, sometimes even surpassing the baseline Pythia model. Below are the results on six datasets from different domains. The evaluation metric is called perplexity and lower perplexity is better. The red line shows the perplexity of Pythia, and the yellow and green lines show the perplexity of the low-risk LLM augmented with in-domain data using two different augmentation strategies and varying amounts of data. You can see that for the news domain (center top), it is possible to outperform the high-risk model if you have access to a datastore of ~1000 million tokens from news articles.
This solution is not ready for prime time, but it’s certainly compelling! The augmentation strategies add latency and Pythia is not a state-of-the-art model to compare against. But if I squint and put on my VC cap, I can imagine a world of Model Builders, Dataset Owners and Data Augmentation Platforms that balances fair compensation for creative work with the utility of high-quality language models.




Comments
Sign in or become a Machines on Paper member to join the conversation.
Just enter your email below to get a log in link.